The Altair Community is migrating to a new platform to provide a better experience for you. In preparation for the migration, the Altair Community is on read-only mode from October 28 - November 6, 2024. Technical support via cases will continue to work as is. For any urgent requests from Students/Faculty members, please submit the form linked here
"Simple Text Classification - Help"

Hello,
I am trying to classifiy documents (.txt) [sort into groups].
What I've dont so far:
Process Documents from Files (2 categories / classes) -> Tokenize -> Filter Stopwords ==> Learner ==> Apply Model (the document to classify comes from Read Document -> Process Documents (Tokenize, Filter) as you can see below:
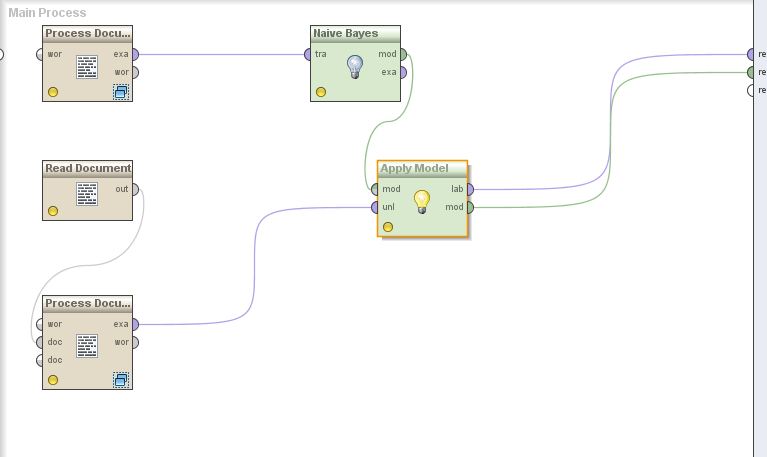
There are 6 documents for each class (Process Documents from Files) and a single document to classify.
Is this the right way to classify text / documents in Rapidminer ? I am asking because the results are confusing..just to make sure, I want Rapidminer to tell me "Your single .txt file belongs to class/category A or B".
Thanks in advanced!
I am trying to classifiy documents (.txt) [sort into groups].
What I've dont so far:
Process Documents from Files (2 categories / classes) -> Tokenize -> Filter Stopwords ==> Learner ==> Apply Model (the document to classify comes from Read Document -> Process Documents (Tokenize, Filter) as you can see below:
There are 6 documents for each class (Process Documents from Files) and a single document to classify.
Is this the right way to classify text / documents in Rapidminer ? I am asking because the results are confusing..just to make sure, I want Rapidminer to tell me "Your single .txt file belongs to class/category A or B".
Thanks in advanced!
Tagged:
0
Answers
you will have to make sure that in the apply case the same word lists are used! Otherwise there won't be the same attributes and the TF-IDF will differ! So forward them from the process documents operator in training part to the input port of Process Documents on application part.
We have a Webinar that will introduce you to the text classification tasks more detailed.
Greetings,
Sebastian