The Altair Community is migrating to a new platform to provide a better experience for you. In preparation for the migration, the Altair Community is on read-only mode from October 28 - November 6, 2024. Technical support via cases will continue to work as is. For any urgent requests from Students/Faculty members, please submit the form linked here
Formulating a test set/training set setup

Hi guys,
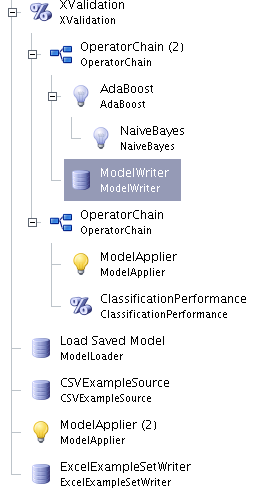
I've been tasked with creating a model on a training set, then applying it to a test set. In order to do this, I have this setup in the GUI: (Sorry about the bad names, just know I am loading the test set at the end!)
It's giving me problems.
a) I don't think saving the model every iteration, then loading it again at the end, is a good thing. It takes a fair chunk of time to write the model out each time. How can I refer back to it? This is particularly bad if I am running feature selection. I have to manually filter out the attributes the feature selecter chose when I load the test set.
b) Putting the boosting in there results in errors. Without the boosting, this works to completion. The errors I get are:
Thanks guys!
I've been tasked with creating a model on a training set, then applying it to a test set. In order to do this, I have this setup in the GUI: (Sorry about the bad names, just know I am loading the test set at the end!)
It's giving me problems.
a) I don't think saving the model every iteration, then loading it again at the end, is a good thing. It takes a fair chunk of time to write the model out each time. How can I refer back to it? This is particularly bad if I am running feature selection. I have to manually filter out the attributes the feature selecter chose when I load the test set.
b) Putting the boosting in there results in errors. Without the boosting, this works to completion. The errors I get are:
It's the NullPointerException that kills it, but I don't know what it's referring to. As I said, removing the boosting, it works fine. Any ideas?
P Jun 3, 2009 9:56:54 PM: [Warning] AdaBoost: The number of nominal values is not the same for training and application for attribute 'state1', training: 53, application: 52
P Jun 3, 2009 9:56:54 PM: [Warning] AdaBoost: The number of nominal values is not the same for training and application for attribute 'domain1', training: 9809, application: 4695
G Jun 3, 2009 9:56:54 PM: [Warning] Distribution: The number of nominal values is not the same for training and application for attribute 'state1', training: 53, application: 52
G Jun 3, 2009 9:56:54 PM: [Warning] Distribution: The number of nominal values is not the same for training and application for attribute 'domain1', training: 9809, application: 4695
G Jun 3, 2009 9:56:54 PM: [Warning] Distribution: The number of nominal values is not the same for training and application for attribute 'state1', training: 53, application: 52
G Jun 3, 2009 9:56:54 PM: [Warning] Distribution: The number of nominal values is not the same for training and application for attribute 'domain1', training: 9809, application: 4695
G Jun 3, 2009 9:56:55 PM: [Warning] Distribution: The number of nominal values is not the same for training and application for attribute 'state1', training: 53, application: 52
G Jun 3, 2009 9:56:55 PM: [Warning] Distribution: The number of nominal values is not the same for training and application for attribute 'domain1', training: 9809, application: 4695
G Jun 3, 2009 9:56:55 PM: [Warning] Distribution: The number of nominal values is not the same for training and application for attribute 'state1', training: 53, application: 52
G Jun 3, 2009 9:56:56 PM: [Warning] Distribution: The number of nominal values is not the same for training and application for attribute 'domain1', training: 9809, application: 4695
G Jun 3, 2009 9:56:56 PM: [Warning] Distribution: The number of nominal values is not the same for training and application for attribute 'state1', training: 53, application: 52
G Jun 3, 2009 9:56:56 PM: [Warning] Distribution: The number of nominal values is not the same for training and application for attribute 'domain1', training: 9809, application: 4695
G Jun 3, 2009 9:56:57 PM: [Fatal] NullPointerException occured in 1st application of ModelApplier (2) (ModelApplier)
G Jun 3, 2009 9:56:57 PM: [Fatal] Process failed: operator cannot be executed. Check the log messages...
Thanks guys!
0
Answers
the XValidation operator has only one purpose: Estimating the performance of a given learner scheme. To achieve this, the models are trained on a subset of the total data and applied on the remaining data. So the model did not see the complete data during training!
This has two effects:
The model is not as good as it would be if applied on the complete training data (the more data the better) and it might happen, that some nominal values are not in the training data. If the model then sees it in the application data, it will fail, ignore it, or using a heuristic to cope this.
So on your specific setup, you should check the parameter "create_complete_model" in the XValidation operator. You can remove the modelWriter and Loader, since the XValidation will return a model. This is learned after the XValidation on the complete data set.
Greetings,
Sebastian
Any ideas about the null pointer exception? It's still happening