The Altair Community is migrating to a new platform to provide a better experience for you. In preparation for the migration, the Altair Community is on read-only mode from October 28 - November 6, 2024. Technical support via cases will continue to work as is. For any urgent requests from Students/Faculty members, please submit the form linked here
Explain Predictions: Ranking attributes that supports and contradicts correct predictions
 varunm1
Member Posts: 1,207
varunm1
Member Posts: 1,207 Hello,
Most of the feature selection techniques will provide us with the best predictors that support predicting target label. These are mainly dependent on the correlation between the predictor and output label(class).
Most of the feature selection techniques will provide us with the best predictors that support predicting target label. These are mainly dependent on the correlation between the predictor and output label(class).
A limitation of this process is the importance of attributes changes from one model to another model. This mainly depends on the variations in the strength of attribute in the presence of other attributes and also based on model statistical background.
How can we know which of these variables performed better in predicting a correct label for a particular algorithm?
In RapidMiner, there is an "explain predictions" operator that provides statistical and visual observations to help understand the role of each attribute on prediction. This operator uses local correlation values to specify each attribute (Predictor) role in predicting a particular value related to a single sample in the data. This role can be supporting or contradicting the prediction. These were visualized beautifully with different color variations in red and green. Red color represents attributes that are contradicting prediction, and green color represents attributes that support the prediction.
How can we know which of these variables performed better in predicting a correct label for a particular algorithm?
In RapidMiner, there is an "explain predictions" operator that provides statistical and visual observations to help understand the role of each attribute on prediction. This operator uses local correlation values to specify each attribute (Predictor) role in predicting a particular value related to a single sample in the data. This role can be supporting or contradicting the prediction. These were visualized beautifully with different color variations in red and green. Red color represents attributes that are contradicting prediction, and green color represents attributes that support the prediction.
How to know which attributes supported and contradicted correct predictions and vice versa?
As explained earlier the color codes you see in visualization belongs to both correct and incorrect prediction. What if you are interested in finding attributes that support and contradicts correct prediction? This is the motive behind writing this post. In predictive modeling, only a few models can provide global importance of variables. Finding attributes of global significance is difficult in the case of complex algorithms. But, with the help of "explain prediction" operator, we can generate rankings for predictions that supported and contradicted predictions. I will explain this in a process example below.
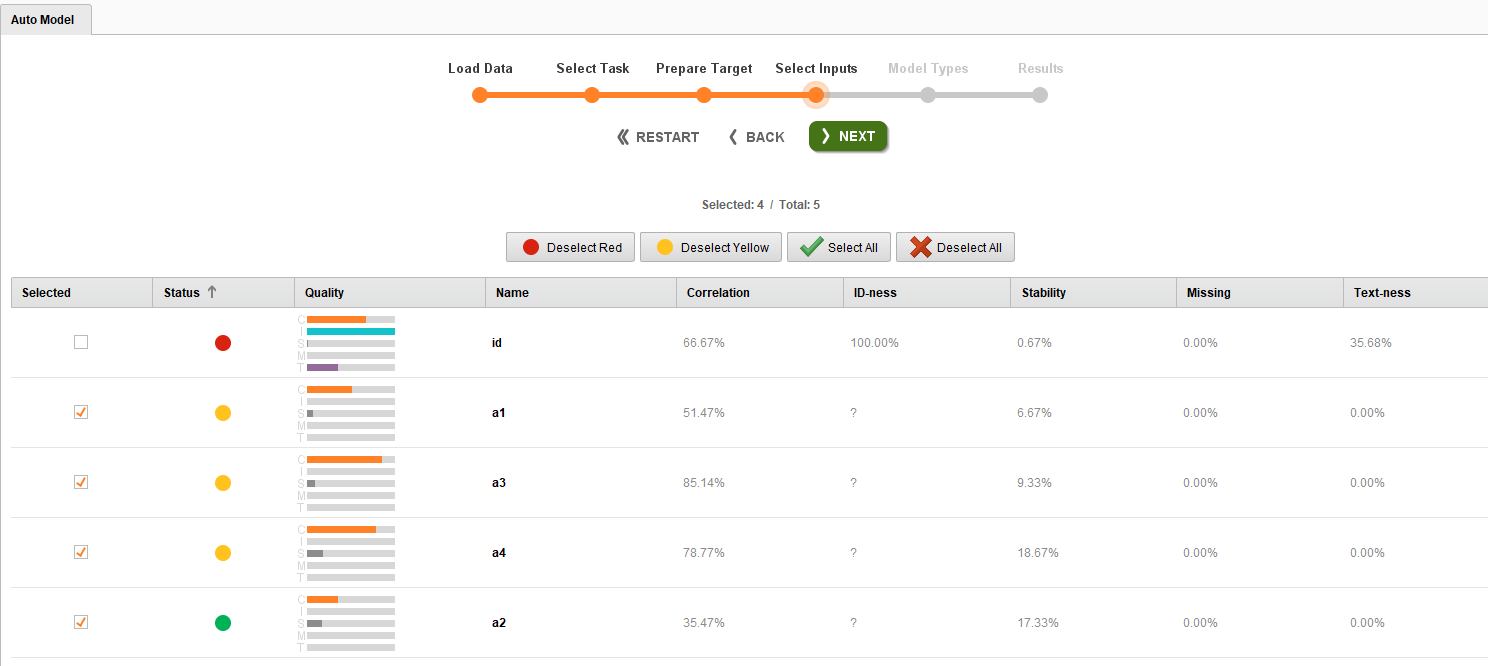
The process file attached below is based on IRIS dataset. The problem we are looking here is related to the classification of different flowers based on four attributes (a1 to a4). I try to find attribute importance using Auto model. An auto model provides important attributes based on four factors (https://docs.rapidminer.com/8.1/studio/auto-model/). Now, I first observed the importance of attributes in the auto model and found that a2 is the best predictor as you can see in below figure its represented in green. The other three attributes are in yellow, and this means that they have a medium impact on model predictions. To test this, I run the models (5 fold cross validation) with these three attributes included and removed.
The process file attached below is based on IRIS dataset. The problem we are looking here is related to the classification of different flowers based on four attributes (a1 to a4). I try to find attribute importance using Auto model. An auto model provides important attributes based on four factors (https://docs.rapidminer.com/8.1/studio/auto-model/). Now, I first observed the importance of attributes in the auto model and found that a2 is the best predictor as you can see in below figure its represented in green. The other three attributes are in yellow, and this means that they have a medium impact on model predictions. To test this, I run the models (5 fold cross validation) with these three attributes included and removed.
Interestingly, the models did very well in the presence of all four attributes compared to their absence. The kappa values increased from 0.3 to 0.9. So, it means that for this dataset we better include all the four attributes. Now, the next task is trying to understand which attributes did well in predicting the correct label. For this, We utilize the explain predictions operator as well as some regular operators to rank the performance ( provided this ranking method).
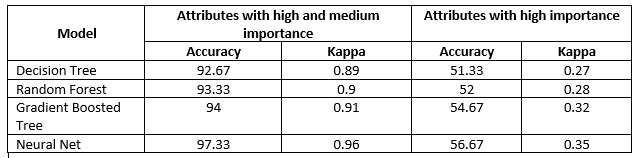
I compare four classification models (Decision Tree, Randon Forest, Gradient Boosted Tree & Neural Network) performance and identify the importance of attributes in each model for correct predictions. From the below figure, you can observe that the importance of each attribute varied according to the algorithm. The positive value indicates supporting attributes and negative indicates contradicting attributes related to correct predictions. These attributes were sorted based on their importance.

Now to observe the effect of having only supporting attributes I removed attributes that were identified above to contradict correct predictions and run the models again. From the results, I observed that the Decision Tree and Gradient boosted tree performance improved. There is no difference in Random forest performance but neural net performance reduced. In machine learning, we try different crazy things as there are no set rules to get better predictions.
Comments and feedback are much appreciated.
Thanks
Now to observe the effect of having only supporting attributes I removed attributes that were identified above to contradict correct predictions and run the models again. From the results, I observed that the Decision Tree and Gradient boosted tree performance improved. There is no difference in Random forest performance but neural net performance reduced. In machine learning, we try different crazy things as there are no set rules to get better predictions.
Comments and feedback are much appreciated.
Thanks
Regards,
Varun
https://www.varunmandalapu.com/
Varun
https://www.varunmandalapu.com/
Be Safe. Follow precautions and Maintain Social Distancing
9
Comments
The colored status bubble provides a quality indicator for a data column.
Ingo
Correct me if there is any misconception about this.
Varun
https://www.varunmandalapu.com/
Be Safe. Follow precautions and Maintain Social Distancing
Varun
https://www.varunmandalapu.com/
Be Safe. Follow precautions and Maintain Social Distancing
I love RM as it is easy to use for beginners to step in big-data analysis world and they can actually conduct some complex projects using RM. However, sometimes it constrains the use of it due to some commonly used functions are missing. I would say feature importance is one of them.
What kind of feature importance algorithm are you looking for?
Varun
https://www.varunmandalapu.com/
Be Safe. Follow precautions and Maintain Social Distancing
This is by the way the thought people use to generate a learner which predicts the uncertainty of another learner, isnt it?
Dortmund, Germany