The Altair Community is migrating to a new platform to provide a better experience for you. In preparation for the migration, the Altair Community is on read-only mode from October 28 - November 6, 2024. Technical support via cases will continue to work as is. For any urgent requests from Students/Faculty members, please submit the form linked here
Missing Attribute when applying model although Training exampleSet and real DataSet are the same
Hi,
I am new to rapidMiner and I am trying to classifly YouTube Comments on Innovation Products into Customer Requirement or not.
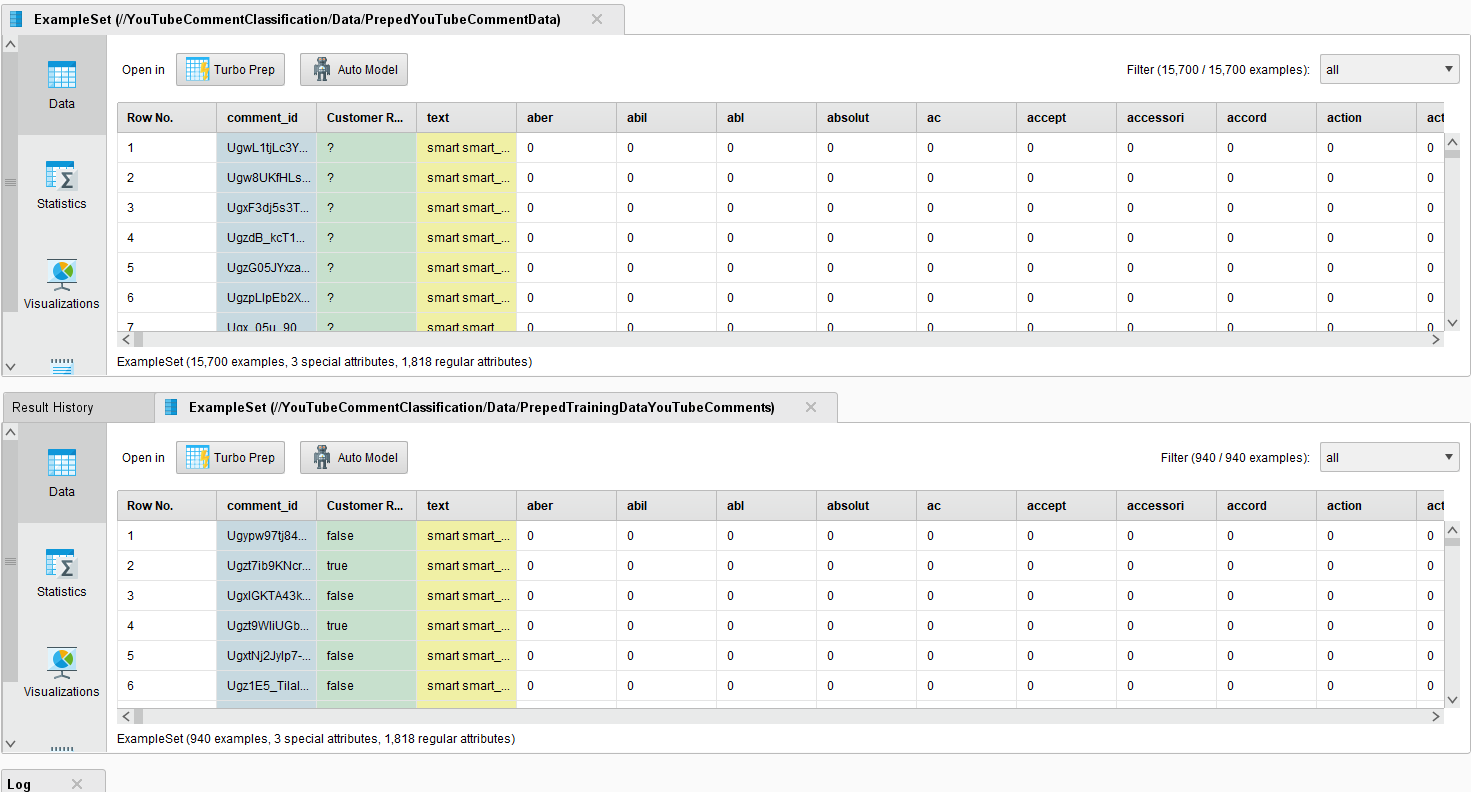
Both ExampleSets should be the same as I used the wordlist from the training data and applied it to the data I want to classify with the Process Documents from Data Operator. In the following picuture you can see a comparison of both DataSets.
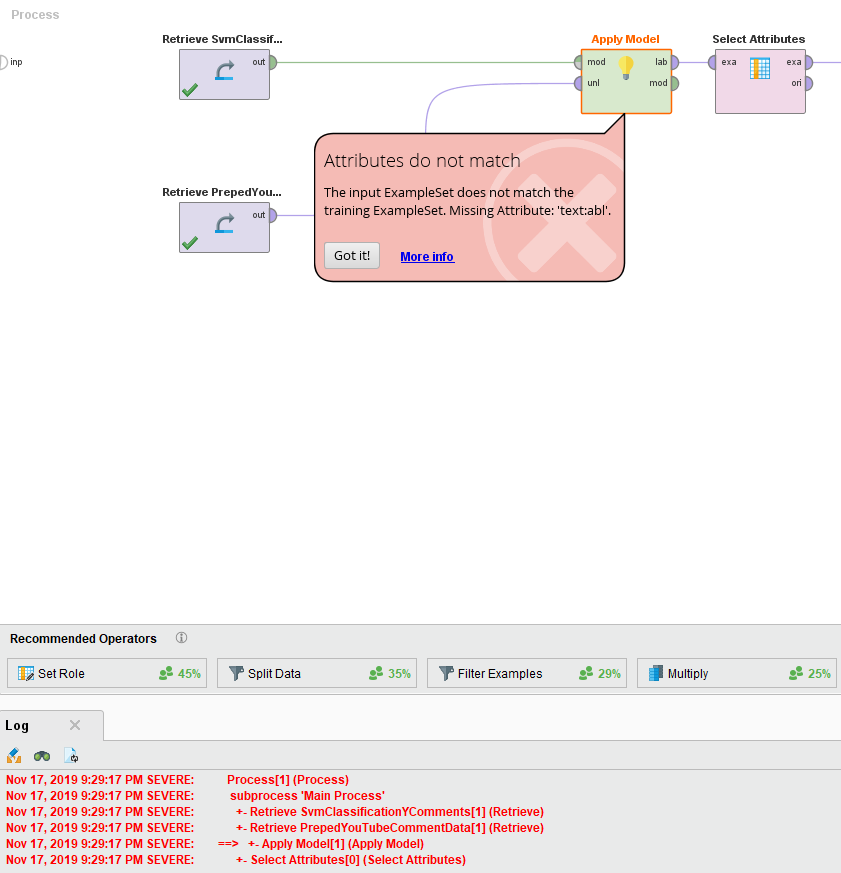
I used RapidMiner Automodel to create an SVM Classification Process and then I stored the Model with this Process. I then used the following Process:
I also attached a 100 rows of my sample Data. I apologize if this problem has already been solved (Couldn't find anything useful for my situation) or if I made some simple mistake.
If someone knows how to correct english spelling, (I already tried the python script using textblob posted in the rapid Miner community. It changes words that are already correct for example "Big" to "Fig") I would also be really grateful.
Thanks in advance,
Tennessee
I am new to rapidMiner and I am trying to classifly YouTube Comments on Innovation Products into Customer Requirement or not.
Both ExampleSets should be the same as I used the wordlist from the training data and applied it to the data I want to classify with the Process Documents from Data Operator. In the following picuture you can see a comparison of both DataSets.
I used RapidMiner Automodel to create an SVM Classification Process and then I stored the Model with this Process. I then used the following Process:
<?xml version="1.0" encoding="UTF-8"?><process version="9.3.001">
<context>
<input/>
<output/>
<macros>
<macro>
<key>text</key>
<value>Lets try the relly simple way. I like smart watches</value>
</macro>
</macros>
</context>
<operator activated="true" class="process" compatibility="9.3.001" expanded="true" name="Process">
<parameter key="logverbosity" value="init"/>
<parameter key="random_seed" value="2001"/>
<parameter key="send_mail" value="never"/>
<parameter key="notification_email" value=""/>
<parameter key="process_duration_for_mail" value="30"/>
<parameter key="encoding" value="SYSTEM"/>
<process expanded="true">
<operator activated="true" class="retrieve" compatibility="9.3.001" expanded="true" height="68" name="Retrieve PrepedYouTubeCommentData" width="90" x="45" y="187">
<parameter key="repository_entry" value="../Data/PrepedYouTubeCommentData"/>
</operator>
<operator activated="true" class="retrieve" compatibility="9.3.001" expanded="true" height="68" name="Retrieve SvmClassificationYComments" width="90" x="45" y="85">
<parameter key="repository_entry" value="../Results/SvmClassificationYComments"/>
</operator>
<operator activated="true" class="apply_model" compatibility="9.3.001" expanded="true" height="82" name="Apply Model" width="90" x="313" y="85">
<list key="application_parameters"/>
<parameter key="create_view" value="false"/>
</operator>
<operator activated="true" class="select_attributes" compatibility="9.3.001" expanded="true" height="82" name="Select Attributes" width="90" x="581" y="85">
<parameter key="attribute_filter_type" value="numeric_value_filter"/>
<parameter key="attribute" value=""/>
<parameter key="attributes" value=""/>
<parameter key="use_except_expression" value="false"/>
<parameter key="value_type" value="attribute_value"/>
<parameter key="use_value_type_exception" value="false"/>
<parameter key="except_value_type" value="time"/>
<parameter key="block_type" value="attribute_block"/>
<parameter key="use_block_type_exception" value="false"/>
<parameter key="except_block_type" value="value_matrix_row_start"/>
<parameter key="numeric_condition" value=">0"/>
<parameter key="invert_selection" value="false"/>
<parameter key="include_special_attributes" value="false"/>
</operator>
<connect from_op="Retrieve PrepedYouTubeCommentData" from_port="output" to_op="Apply Model" to_port="unlabelled data"/>
<connect from_op="Retrieve SvmClassificationYComments" from_port="output" to_op="Apply Model" to_port="model"/>
<connect from_op="Apply Model" from_port="labelled data" to_op="Select Attributes" to_port="example set input"/>
<connect from_op="Select Attributes" from_port="example set output" to_port="result 1"/>
<portSpacing port="source_input 1" spacing="0"/>
<portSpacing port="sink_result 1" spacing="0"/>
<portSpacing port="sink_result 2" spacing="0"/>
</process>
</operator>
</process>
However I always get this error:
I used this tutorial on youTube with the videoid VbNhvYQZ2v0 and the rapidMiner Academy TextMining and Machine Learning course to construct my Processes.
This Process shows my Preprocessing for my Training Data:
And this Process shows my Preprocessing for my Data I want to classify:
I used this tutorial on youTube with the videoid VbNhvYQZ2v0 and the rapidMiner Academy TextMining and Machine Learning course to construct my Processes.
This Process shows my Preprocessing for my Training Data:
<?xml version="1.0" encoding="UTF-8"?><process version="9.3.001">
<context>
<input/>
<output/>
<macros/>
</context>
<operator activated="true" class="process" compatibility="9.3.001" expanded="true" name="Process">
<parameter key="logverbosity" value="init"/>
<parameter key="random_seed" value="2001"/>
<parameter key="send_mail" value="never"/>
<parameter key="notification_email" value=""/>
<parameter key="process_duration_for_mail" value="30"/>
<parameter key="encoding" value="SYSTEM"/>
<process expanded="true">
<operator activated="true" class="retrieve" compatibility="9.3.001" expanded="true" height="68" name="Retrieve" width="90" x="112" y="340">
<parameter key="repository_entry" value="../Data/SampleDataYouTubeComments"/>
</operator>
<operator activated="true" class="nominal_to_text" compatibility="9.3.001" expanded="true" height="82" name="Nominal to Text" width="90" x="45" y="187">
<parameter key="attribute_filter_type" value="subset"/>
<parameter key="attribute" value="comment"/>
<parameter key="attributes" value="|comment|product_name|product_type"/>
<parameter key="use_except_expression" value="false"/>
<parameter key="value_type" value="nominal"/>
<parameter key="use_value_type_exception" value="false"/>
<parameter key="except_value_type" value="file_path"/>
<parameter key="block_type" value="single_value"/>
<parameter key="use_block_type_exception" value="false"/>
<parameter key="except_block_type" value="single_value"/>
<parameter key="invert_selection" value="false"/>
<parameter key="include_special_attributes" value="false"/>
</operator>
<operator activated="true" class="text:process_document_from_data" compatibility="8.2.000" expanded="true" height="82" name="Process Documents from Data" width="90" x="45" y="34">
<parameter key="create_word_vector" value="true"/>
<parameter key="vector_creation" value="TF-IDF"/>
<parameter key="add_meta_information" value="true"/>
<parameter key="keep_text" value="true"/>
<parameter key="prune_method" value="absolute"/>
<parameter key="prune_below_percent" value="3.0"/>
<parameter key="prune_above_percent" value="30.0"/>
<parameter key="prune_below_absolute" value="2"/>
<parameter key="prune_above_absolute" value="1000"/>
<parameter key="prune_below_rank" value="0.05"/>
<parameter key="prune_above_rank" value="0.95"/>
<parameter key="datamanagement" value="double_sparse_array"/>
<parameter key="data_management" value="auto"/>
<parameter key="select_attributes_and_weights" value="false"/>
<list key="specify_weights"/>
<process expanded="true">
<operator activated="true" class="text:tokenize" compatibility="8.2.000" expanded="true" height="68" name="Tokenize" width="90" x="45" y="34">
<parameter key="mode" value="non letters"/>
<parameter key="characters" value=".:"/>
<parameter key="language" value="English"/>
<parameter key="max_token_length" value="3"/>
</operator>
<operator activated="true" class="text:transform_cases" compatibility="8.2.000" expanded="true" height="68" name="Transform Cases" width="90" x="179" y="34">
<parameter key="transform_to" value="lower case"/>
</operator>
<operator activated="true" class="text:filter_stopwords_english" compatibility="8.2.000" expanded="true" height="68" name="Filter Stopwords (English)" width="90" x="313" y="34"/>
<operator activated="true" class="text:stem_porter" compatibility="8.2.000" expanded="true" height="68" name="Stem (Porter)" width="90" x="447" y="34"/>
<operator activated="true" class="text:generate_n_grams_terms" compatibility="8.2.000" expanded="true" height="68" name="Generate n-Grams (Terms)" width="90" x="581" y="34">
<parameter key="max_length" value="2"/>
</operator>
<operator activated="true" class="text:filter_by_length" compatibility="8.2.000" expanded="true" height="68" name="Filter Tokens (by Length)" width="90" x="782" y="34">
<parameter key="min_chars" value="2"/>
<parameter key="max_chars" value="25"/>
</operator>
<connect from_port="document" to_op="Tokenize" to_port="document"/>
<connect from_op="Tokenize" from_port="document" to_op="Transform Cases" to_port="document"/>
<connect from_op="Transform Cases" from_port="document" to_op="Filter Stopwords (English)" to_port="document"/>
<connect from_op="Filter Stopwords (English)" from_port="document" to_op="Stem (Porter)" to_port="document"/>
<connect from_op="Stem (Porter)" from_port="document" to_op="Generate n-Grams (Terms)" to_port="document"/>
<connect from_op="Generate n-Grams (Terms)" from_port="document" to_op="Filter Tokens (by Length)" to_port="document"/>
<connect from_op="Filter Tokens (by Length)" from_port="document" to_port="document 1"/>
<portSpacing port="source_document" spacing="0"/>
<portSpacing port="sink_document 1" spacing="0"/>
<portSpacing port="sink_document 2" spacing="0"/>
</process>
</operator>
<operator activated="true" class="store" compatibility="9.3.001" expanded="true" height="68" name="Store Wordlist" width="90" x="782" y="85">
<parameter key="repository_entry" value="../Results/WordlistForCR"/>
</operator>
<operator activated="true" class="numerical_to_polynominal" compatibility="9.3.001" expanded="true" height="82" name="Numerical to Polynominal" width="90" x="179" y="34">
<parameter key="attribute_filter_type" value="single"/>
<parameter key="attribute" value="Customer Requirement"/>
<parameter key="attributes" value=""/>
<parameter key="use_except_expression" value="false"/>
<parameter key="value_type" value="numeric"/>
<parameter key="use_value_type_exception" value="false"/>
<parameter key="except_value_type" value="real"/>
<parameter key="block_type" value="value_series"/>
<parameter key="use_block_type_exception" value="false"/>
<parameter key="except_block_type" value="value_series_end"/>
<parameter key="invert_selection" value="false"/>
<parameter key="include_special_attributes" value="false"/>
</operator>
<operator activated="true" class="map" compatibility="9.3.001" expanded="true" height="82" name="Map" width="90" x="313" y="34">
<parameter key="attribute_filter_type" value="single"/>
<parameter key="attribute" value="Customer Requirement"/>
<parameter key="attributes" value=""/>
<parameter key="use_except_expression" value="false"/>
<parameter key="value_type" value="attribute_value"/>
<parameter key="use_value_type_exception" value="false"/>
<parameter key="except_value_type" value="time"/>
<parameter key="block_type" value="attribute_block"/>
<parameter key="use_block_type_exception" value="false"/>
<parameter key="except_block_type" value="value_matrix_row_start"/>
<parameter key="invert_selection" value="false"/>
<parameter key="include_special_attributes" value="false"/>
<list key="value_mappings">
<parameter key="1" value="true"/>
<parameter key="0" value="false"/>
</list>
<parameter key="consider_regular_expressions" value="false"/>
<parameter key="add_default_mapping" value="false"/>
</operator>
<operator activated="true" class="set_role" compatibility="9.3.001" expanded="true" height="82" name="Set Role" width="90" x="447" y="34">
<parameter key="attribute_name" value="Customer Requirement"/>
<parameter key="target_role" value="label"/>
<list key="set_additional_roles">
<parameter key="comment_id" value="id"/>
</list>
</operator>
<operator activated="true" class="store" compatibility="9.3.001" expanded="true" height="68" name="Store" width="90" x="581" y="34">
<parameter key="repository_entry" value="../Data/PrepedTrainingDataYouTubeComments"/>
</operator>
<connect from_op="Retrieve" from_port="output" to_op="Nominal to Text" to_port="example set input"/>
<connect from_op="Nominal to Text" from_port="example set output" to_op="Process Documents from Data" to_port="example set"/>
<connect from_op="Process Documents from Data" from_port="example set" to_op="Numerical to Polynominal" to_port="example set input"/>
<connect from_op="Process Documents from Data" from_port="word list" to_op="Store Wordlist" to_port="input"/>
<connect from_op="Store Wordlist" from_port="through" to_port="result 2"/>
<connect from_op="Numerical to Polynominal" from_port="example set output" to_op="Map" to_port="example set input"/>
<connect from_op="Map" from_port="example set output" to_op="Set Role" to_port="example set input"/>
<connect from_op="Set Role" from_port="example set output" to_port="result 1"/>
<portSpacing port="source_input 1" spacing="0"/>
<portSpacing port="sink_result 1" spacing="0"/>
<portSpacing port="sink_result 2" spacing="0"/>
<portSpacing port="sink_result 3" spacing="0"/>
</process>
</operator>
</process>
And this Process shows my Preprocessing for my Data I want to classify:
<?xml version="1.0" encoding="UTF-8"?><process version="9.3.001">
<context>
<input/>
<output/>
<macros/>
</context>
<operator activated="true" class="process" compatibility="9.3.001" expanded="true" name="Process">
<parameter key="logverbosity" value="init"/>
<parameter key="random_seed" value="2001"/>
<parameter key="send_mail" value="never"/>
<parameter key="notification_email" value=""/>
<parameter key="process_duration_for_mail" value="30"/>
<parameter key="encoding" value="SYSTEM"/>
<process expanded="true">
<operator activated="true" class="retrieve" compatibility="9.3.001" expanded="true" height="68" name="Retrieve WordlistForCR" width="90" x="45" y="187">
<parameter key="repository_entry" value="../Results/WordlistForCR"/>
</operator>
<operator activated="true" class="retrieve" compatibility="9.3.001" expanded="true" height="68" name="Retrieve DataYouTubeComments" width="90" x="112" y="289">
<parameter key="repository_entry" value="../Data/DataYouTubeComments"/>
</operator>
<operator activated="true" class="nominal_to_text" compatibility="9.3.001" expanded="true" height="82" name="Nominal to Text" width="90" x="246" y="289">
<parameter key="attribute_filter_type" value="subset"/>
<parameter key="attribute" value="comment"/>
<parameter key="attributes" value="|comment|product_name|product_type"/>
<parameter key="use_except_expression" value="false"/>
<parameter key="value_type" value="nominal"/>
<parameter key="use_value_type_exception" value="false"/>
<parameter key="except_value_type" value="file_path"/>
<parameter key="block_type" value="single_value"/>
<parameter key="use_block_type_exception" value="false"/>
<parameter key="except_block_type" value="single_value"/>
<parameter key="invert_selection" value="false"/>
<parameter key="include_special_attributes" value="false"/>
</operator>
<operator activated="true" class="text:process_document_from_data" compatibility="8.2.000" expanded="true" height="82" name="Process Documents from Data" width="90" x="246" y="187">
<parameter key="create_word_vector" value="true"/>
<parameter key="vector_creation" value="TF-IDF"/>
<parameter key="add_meta_information" value="true"/>
<parameter key="keep_text" value="true"/>
<parameter key="prune_method" value="none"/>
<parameter key="prune_below_percent" value="3.0"/>
<parameter key="prune_above_percent" value="30.0"/>
<parameter key="prune_below_rank" value="0.05"/>
<parameter key="prune_above_rank" value="0.95"/>
<parameter key="datamanagement" value="double_sparse_array"/>
<parameter key="data_management" value="auto"/>
<parameter key="select_attributes_and_weights" value="false"/>
<list key="specify_weights"/>
<process expanded="true">
<operator activated="true" class="text:tokenize" compatibility="8.2.000" expanded="true" height="68" name="Tokenize (2)" width="90" x="112" y="34">
<parameter key="mode" value="non letters"/>
<parameter key="characters" value=".:"/>
<parameter key="language" value="English"/>
<parameter key="max_token_length" value="3"/>
</operator>
<operator activated="true" class="text:transform_cases" compatibility="8.2.000" expanded="true" height="68" name="Transform Cases (2)" width="90" x="380" y="34">
<parameter key="transform_to" value="lower case"/>
</operator>
<operator activated="true" class="text:stem_porter" compatibility="8.2.000" expanded="true" height="68" name="Stem (Porter) (2)" width="90" x="581" y="34"/>
<operator activated="true" class="text:generate_n_grams_terms" compatibility="8.2.000" expanded="true" height="68" name="Generate n-Grams (Terms) (2)" width="90" x="715" y="34">
<parameter key="max_length" value="2"/>
</operator>
<connect from_port="document" to_op="Tokenize (2)" to_port="document"/>
<connect from_op="Tokenize (2)" from_port="document" to_op="Transform Cases (2)" to_port="document"/>
<connect from_op="Transform Cases (2)" from_port="document" to_op="Stem (Porter) (2)" to_port="document"/>
<connect from_op="Stem (Porter) (2)" from_port="document" to_op="Generate n-Grams (Terms) (2)" to_port="document"/>
<connect from_op="Generate n-Grams (Terms) (2)" from_port="document" to_port="document 1"/>
<portSpacing port="source_document" spacing="0"/>
<portSpacing port="sink_document 1" spacing="0"/>
<portSpacing port="sink_document 2" spacing="0"/>
</process>
</operator>
<operator activated="true" class="generate_empty_attribute" compatibility="9.3.001" expanded="true" height="82" name="Generate Empty Attribute" width="90" x="380" y="187">
<parameter key="name" value="Customer Requirement"/>
<parameter key="value_type" value="polynominal"/>
</operator>
<operator activated="true" class="map" compatibility="9.3.001" expanded="true" height="82" name="Map" width="90" x="514" y="187">
<parameter key="attribute_filter_type" value="single"/>
<parameter key="attribute" value="Customer Requirement"/>
<parameter key="attributes" value=""/>
<parameter key="use_except_expression" value="false"/>
<parameter key="value_type" value="attribute_value"/>
<parameter key="use_value_type_exception" value="false"/>
<parameter key="except_value_type" value="time"/>
<parameter key="block_type" value="attribute_block"/>
<parameter key="use_block_type_exception" value="false"/>
<parameter key="except_block_type" value="value_matrix_row_start"/>
<parameter key="invert_selection" value="false"/>
<parameter key="include_special_attributes" value="false"/>
<list key="value_mappings">
<parameter key="1" value="true"/>
<parameter key="0" value="false"/>
</list>
<parameter key="consider_regular_expressions" value="false"/>
<parameter key="add_default_mapping" value="false"/>
</operator>
<operator activated="true" class="set_role" compatibility="9.3.001" expanded="true" height="82" name="Set Role" width="90" x="715" y="187">
<parameter key="attribute_name" value="Customer Requirement"/>
<parameter key="target_role" value="label"/>
<list key="set_additional_roles">
<parameter key="comment_id" value="id"/>
</list>
</operator>
<operator activated="true" class="store" compatibility="9.3.001" expanded="true" height="68" name="Store" width="90" x="849" y="187">
<parameter key="repository_entry" value="../Data/PrepedYouTubeCommentData"/>
</operator>
<connect from_op="Retrieve WordlistForCR" from_port="output" to_op="Process Documents from Data" to_port="word list"/>
<connect from_op="Retrieve DataYouTubeComments" from_port="output" to_op="Nominal to Text" to_port="example set input"/>
<connect from_op="Nominal to Text" from_port="example set output" to_op="Process Documents from Data" to_port="example set"/>
<connect from_op="Process Documents from Data" from_port="example set" to_op="Generate Empty Attribute" to_port="example set input"/>
<connect from_op="Generate Empty Attribute" from_port="example set output" to_op="Map" to_port="example set input"/>
<connect from_op="Map" from_port="example set output" to_op="Set Role" to_port="example set input"/>
<connect from_op="Set Role" from_port="example set output" to_op="Store" to_port="input"/>
<connect from_op="Store" from_port="through" to_port="result 1"/>
<portSpacing port="source_input 1" spacing="0"/>
<portSpacing port="sink_result 1" spacing="0"/>
<portSpacing port="sink_result 2" spacing="0"/>
</process>
</operator>
</process>
I also attached a 100 rows of my sample Data. I apologize if this problem has already been solved (Couldn't find anything useful for my situation) or if I made some simple mistake.
If someone knows how to correct english spelling, (I already tried the python script using textblob posted in the rapid Miner community. It changes words that are already correct for example "Big" to "Fig") I would also be really grateful.
Thanks in advance,
Tennessee
Tagged:
0
Best Answer
-
 Tennessee
Member Posts: 5
Tennessee
Member Posts: 5  Learner I
Okay so I copied the svm model operator from the automodell process that was created into a cross validation and created a another model. In this model I can feed the data that I need to classify, without getting the error message. Now it works smoothly. But still 3 days wasted.
Learner I
Okay so I copied the svm model operator from the automodell process that was created into a cross validation and created a another model. In this model I can feed the data that I need to classify, without getting the error message. Now it works smoothly. But still 3 days wasted.
Hence I recommend if you have problems with the model created by the automodler, copy the model into a cross validation.0
Answers
Scott
Lindon Ventures
Data Science Consulting from Certified RapidMiner Experts
Thanks in advance,
Tennessee
I used rapidminer automodell to create this model and it can't even except its own training data. Something seems very wrong. I'll try manually creating the model.